
기록하는 공간
끄적끄적 서비스 조회 부하 테스트 1편: 이렇게 차이가 많이 난다고? 본문
문제 정의
현재 진행 중인 끄적끄적 프로젝트에서 블록 개수가 많아질수록 조회 성능이 느려진다는 피드백을 받았다.
(블록 개수가 10개, 20개일 때는 문제가 없지만, 점점 많아지게 되면 성능 저하가 체감되었다.)
초기에는 이 문제가 단순히 서버 성능 때문이라고 판단했다.
현재 AWS EC2 t2.micro 인스턴스(CPU 1개, 메모리 1GB)를 사용 중이기 때문이다.
그러나 다른 프로젝트에서 동일한 서버 스펙으로 성능 문제가 없었던 점을 감안해 이번에는 쿼리 및 로직 최적화에 집중하기로 했다.
문제 원인 분석

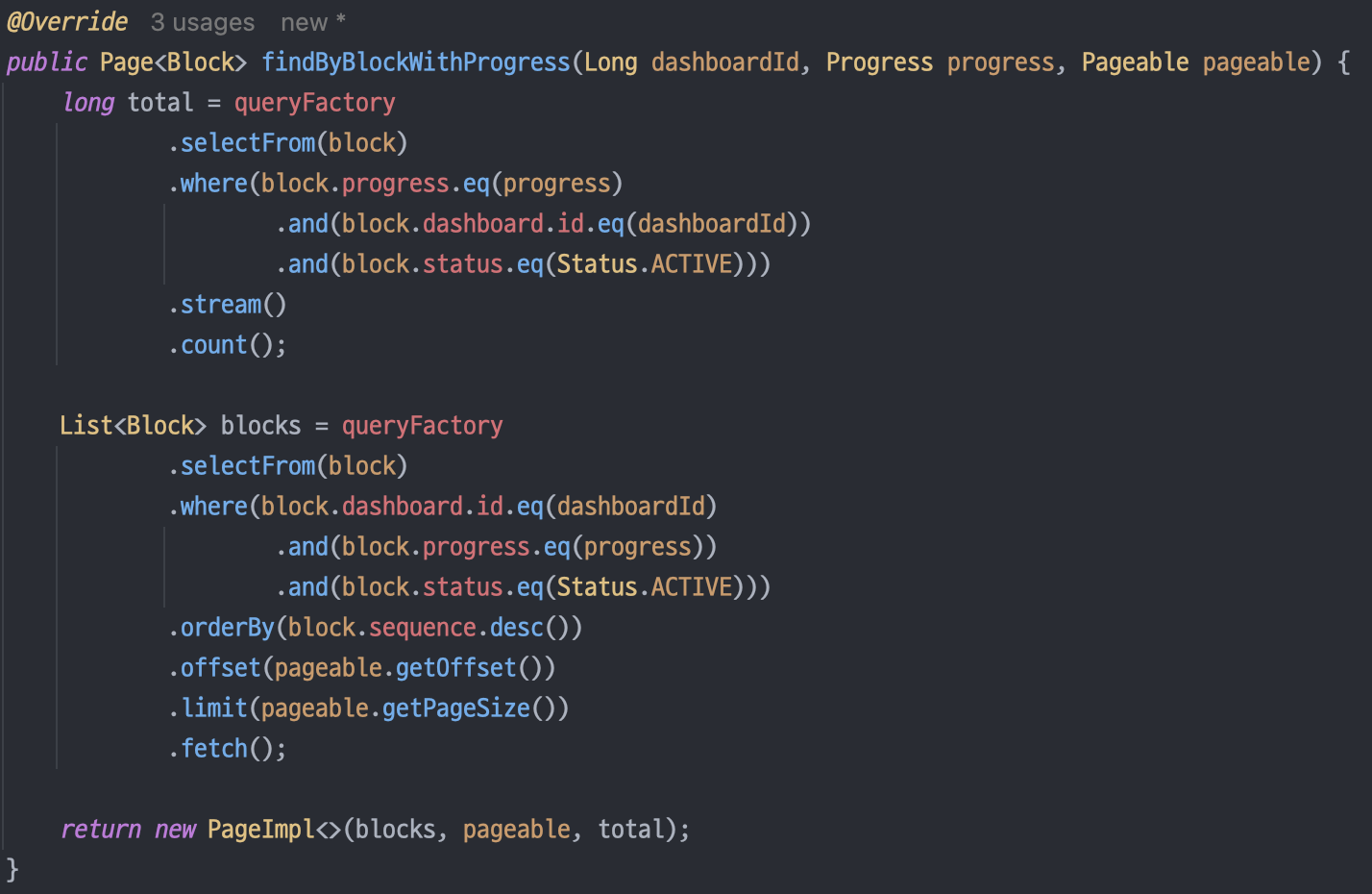
아래는 위 사진과 같이 기존 코드를 실행했을 때의 쿼리이다.
Hibernate:
select * from member where email=?
Hibernate:
select * from block where progress=? and dashboard_id=? and status=?
Hibernate:
select * from block where dashboard_id=? and progress=? and status=? order by sequence desc limit ?, ?
Hibernate:
select * from dashboard left join personal_dashboard on dashboard.id=personal_dashboard.id left join member on member.id=dashboard.member_id where dashboard.id=?
Hibernate:
select * from block join dashboard on dashboard.id=block.dashboard_id join member on member.id=block.member_id where dashboard_id=? and progress=? and status=? order by sequence desc limit ?, ?
Hibernate:
select count(*) from block where dashboard_id=? and progress=? and status=?
여기서 기존 코드와 Hibernate를 분석해 본 결과 아래의 3가지와 같은 문제가 나왔다.
- 중복 및 불필요한 쿼리 호출
- memberRepository.findByEmail 쿼리가 단순히 예외 처리를 위해 호출된다. 결과적으로 사용되지 않는 데이터를 조회하고 있다.
- queryFactory에서 블록 조회 시 전체 블록 데이터를 로드한 후 count() 수행으로 불필요한 메모리를 사용하고 있다.
- Pagination 쿼리의 비효율성
- 데이터 조회와 별도로 count() 쿼리를 추가로 호출한다.
- 페이징 쿼리와 전체 데이터 스캔 쿼리가 각각 실행되어 쿼리 호출 횟수가 증가한다.
- DTO 변환 과정에서 메모리 사용 증가
- blocks.stream().map() 방식으로 변환 시 추가 메모리 및 처리 시간을 소모한다.
해결 과정
위의 3가지 문제를 해결하여 로직을 최적화 한다.
사용하지 않는 데이터 조회는 제거하고, QueryDSL을 사용하여 DTO로 직접 매핑하여 불필요한 엔티티 조회 및 변환 과정을 제거한다. 그리고 총 데이터 개수를 계산하는 count 쿼리를 별도로 실행하여 페이징 처리의 정확성을 높인다.
아래는 수정한 코드이다.
최적화 후
@Override
public Page<BlockInfoResDto> findForBlockByProgress(Long dashboardId, Progress progress, Pageable pageable) {
List<BlockInfoResDto> blockInfoResDtoList = queryFactory
.select(Projections.constructor(BlockInfoResDto.class,
block.id, block.title, block.contents, block.progress, block.type,
block.dashboard.dType, block.startDate, block.deadLine,
block.member.nickname, block.member.picture, block.deadLine))
.from(block)
.where(block.dashboard.id.eq(dashboardId)
.and(block.progress.eq(progress))
.and(block.status.eq(Status.ACTIVE)))
.orderBy(block.sequence.desc())
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetch();
List<BlockInfoResDto> result = blockInfoResDtoList.stream()
.map(blockInfo -> {
String dDay = calculateDDay(blockInfo.deadLine());
return new BlockInfoResDto(
blockInfo.blockId(), blockInfo.title(), blockInfo.contents(),
blockInfo.progress(), blockInfo.type(), blockInfo.dType(),
blockInfo.startDate(), blockInfo.deadLine(), blockInfo.nickname(),
blockInfo.picture(), dDay
);
}).toList();
long total = Objects.requireNonNull(queryFactory
.select(block.id.count())
.from(block)
.where(block.dashboard.id.eq(dashboardId)
.and(block.progress.eq(progress))
.and(block.status.eq(Status.ACTIVE)))
.fetchOne());
return new PageImpl<>(result, pageable, total);
}최적화 방법
1) 중복 쿼리를 제거한다.
2) Projections.constructor로 필요한 필드만 조회하여 메모리 사용량을 최소화한다.
🔗 Projections을 선택한 이유는?
Projections이란, 엔티티를 직접 조회하지 않고 필요한 데이터만 선택적으로 가져와 불필요한 데이터 로딩을 방지함으로써 성능을 향상시킬 수 있는 방법이다.
이번 로직에서 Projections을 사용한 이유는 해당 구조가 변경 가능성이 낮은 화면을 대상으로 하기 때문이다. 따라서, Projections을 통해 필요한 데이터만 정확히 가져오는 것이 적합하다고 판단했다.
특히, 단순히 블록 정보를 조회하는 역할을 하므로, 성능에 최적화된 쿼리를 작성할 수 있다는 점에서 효율적이다. 다만, Projections은 엔티티를 기반으로 한 객체지향적 접근은 아니기 때문에 데이터 변경 추적이나 영속성 컨텍스트와의 연동은 불가능하다.
그럼에도 불구하고, 현재 요구사항과 성능 최적화를 고려한 현실적인 선택으로, 해당 방식을 채택했다.
3) Pagination 쿼리와 count 쿼리 분리로 효율적인 페이징 처리
코드를 수정한 후 부하 테스트를 진행한다.
성능 테스트 결과
환경
테스트 툴: k6
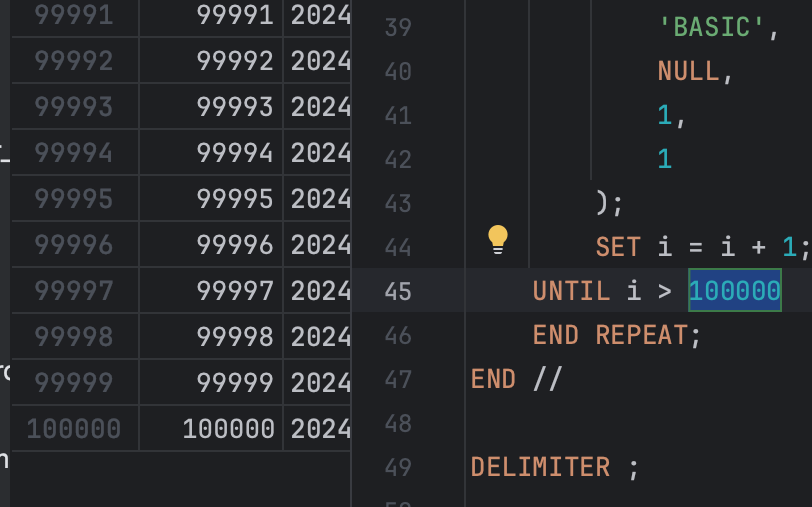
블록 개수: 100,000개
테스트 조건: 10 VUs, 1분 동안 지속적인 부하 생성
import http from "k6/http";
import { sleep } from "k6";
export let options = {
vus: 10, // 가상의 유저 수
duration: "1m", // 테스트 진행 시간
};
export default function () {
let getUrl = {테스트할 api};
http.get(getUrl);
sleep(1);
}
부하 테스트 결과
아래의 테스트 결과는 위와 같은 환경으로 최적화 전후 테스트를 각각 10회 실행하여 평균값을 도출한 결과이다.
최적화 전
data_received..................: 2.3 GB 35 MB/s
data_sent......................: 13 kB 201 B/s
http_req_blocked...............: avg=127.36µs min=3µs med=7µs max=1.23ms p(90)=434.5µs p(95)=1.22ms
http_req_connecting............: avg=37.77µs min=0s med=0s max=442µs p(90)=100.5µs p(95)=378.49µs
http_req_duration..............: avg=5.49s min=3.62s med=5.2s max=7.92s p(90)=7.13s p(95)=7.9s
{ expected_response:true }...: avg=5.49s min=3.62s med=5.2s max=7.92s p(90)=7.13s p(95)=7.9s
http_req_failed................: 0.00% 0 out of 96
http_req_receiving.............: avg=237.22ms min=113.76ms med=200.99ms max=555.48ms p(90)=429.07ms p(95)=525.01ms
http_req_sending...............: avg=37.35µs min=9µs med=25µs max=161µs p(90)=68.5µs p(95)=131.24µs
http_req_tls_handshaking.......: avg=0s min=0s med=0s max=0s p(90)=0s p(95)=0s
http_req_waiting...............: avg=5.26s min=3.51s med=5.01s max=7.38s p(90)=6.77s p(95)=7.38s
http_reqs......................: 96 1.490259/s
iteration_duration.............: avg=6.5s min=4.62s med=6.2s max=8.92s p(90)=8.14s p(95)=8.91s
iterations.....................: 96 1.490259/s
vus............................: 1 min=1 max=10
vus_max........................: 10 min=10 max=10
최적화 후
data_received..................: 4.3 GB 70 MB/s
data_sent......................: 25 kB 398 B/s
http_req_blocked...............: avg=58.12µs min=3µs med=7µs max=1.1ms p(90)=13µs p(95)=424.29µs
http_req_connecting............: avg=15.67µs min=0s med=0s max=379µs p(90)=0s p(95)=186.29µs
http_req_duration..............: avg=2.34s min=1.36s med=2.16s max=4.92s p(90)=2.92s p(95)=4.74s
{ expected_response:true }...: avg=2.34s min=1.36s med=2.16s max=4.92s p(90)=2.92s p(95)=4.74s
http_req_failed................: 0.00% 0 out of 183
http_req_receiving.............: avg=189.73ms min=96.54ms med=173.96ms max=495.27ms p(90)=225.14ms p(95)=472.17ms
http_req_sending...............: avg=42.14µs min=10µs med=22µs max=511µs p(90)=55.2µs p(95)=193.99µs
http_req_tls_handshaking.......: avg=0s min=0s med=0s max=0s p(90)=0s p(95)=0s
http_req_waiting...............: avg=2.15s min=1.2s med=2s max=4.43s p(90)=2.76s p(95)=4.3s
http_reqs......................: 183 2.945099/s
iteration_duration.............: avg=3.34s min=2.36s med=3.16s max=5.92s p(90)=3.92s p(95)=5.74s
iterations.....................: 183 2.945099/s
vus............................: 3 min=3 max=10
vus_max........................: 10 min=10 max=10
아래와 같이 최적화 전과 후의 결과를 보기 좋게 표로 정리하였다.
| 항목 | 최적화 전 | 최적화 후 | 변화 |
| 데이터 수신량 | 2.3 GB (35 MB/s) | 4.3 GB (70 MB/s) | +87% |
| http_req_duration (HTTP 평균 요청 처리 시간) |
5.49s | 2.34s | -57.3% |
| HTTP 요청 수 | 96 요청 (1.49 요청/초) | 183 요청 (2.95 요청/초) | +90.6% |
| HTTP 요청 수신 대기 시간 | 237.22ms | 189.73ms | -20.0% |
| http_req_waiting (HTTP 평균 요청 대기 시간) |
5.26s | 2.15s | -59.1% |
| 총 요청 실패율 | 0.00% (0 실패) | 0.00% (0 실패) | 0% |
| 총 요청 수 | 96 요청 | 183 요청 | +90.6% |
| iteration 평균 시간 (하나의 테스트가 실행되는 데 걸리는 시간) |
6.5s | 3.34s | -48.3% |
최적화 후 성능 개선을 요약하면 이와 같다.
- 평균 요청 처리 시간: 약 57% 감소 (5.49s → 2.34s)
- 평균 요청 대기 시간: 약 59% 감소 (5.26s → 2.15s)
- HTTP 요청 수: 90.6% 증가 (96 → 183)
- HTTP 요청 수신 대기 시간: 20% 감소 (237.22ms → 189.73ms)
- iteration 평균 시간: 약 48% 감소 (6.5s → 3.34s)
마무리
쿼리 최적화와 데이터 처리 방식을 개선하여, 평균 요청 처리 시간과 대기 시간을 각각 약 57%, 59% 감소시켰다. 또한, 더 많은 요청을 처리할 수 있게 되어 시스템 성능을 크게 향상했다.
그리고 부하 테스트를 통해 실제 환경에서의 성능 문제를 미리 파악할 수 있었고, 최적화가 얼마나 중요한지 실감할 수 있었다. 대용량 데이터를 처리할 때 발생할 수 있는 성능 이슈를 해결하는 데 큰 도움이 되었다.
현재는 쿼리 및 로직 최적화에 집중하였지만 추후에는 캐싱 전략이나 인덱싱을 통해 조회 성능을 더욱 향상할 계획이다. 또한, 지속적인 성능 모니터링을 통해 최적화 작업을 계속해서 진행할 예정이다.
끄적끄적 서비스 링크 > https://kkeujeok-kkeujeok.vercel.app/
끄적끄적 프로젝트 깃허브 링크 > https://github.com/AJD-Archive
'프로젝트' 카테고리의 다른 글
| CustomException 그룹화하기 (0) | 2024.02.05 |
|---|
